What's Good: A Live AI News Analyst
Architecting a stateful, distributed RAG application deployed on AWS.
The Engineering Goal
Most basic Retrieval-Augmented Generation (RAG) applications function as stateless semantic search engines. They lack memory and temporal awareness—happily recommending a six-month-old article purely based on vector similarity. My goal was to build a stateful AI news analyst that dynamically adjusts to user interactions in real-time, deployed via a scalable microservices architecture.
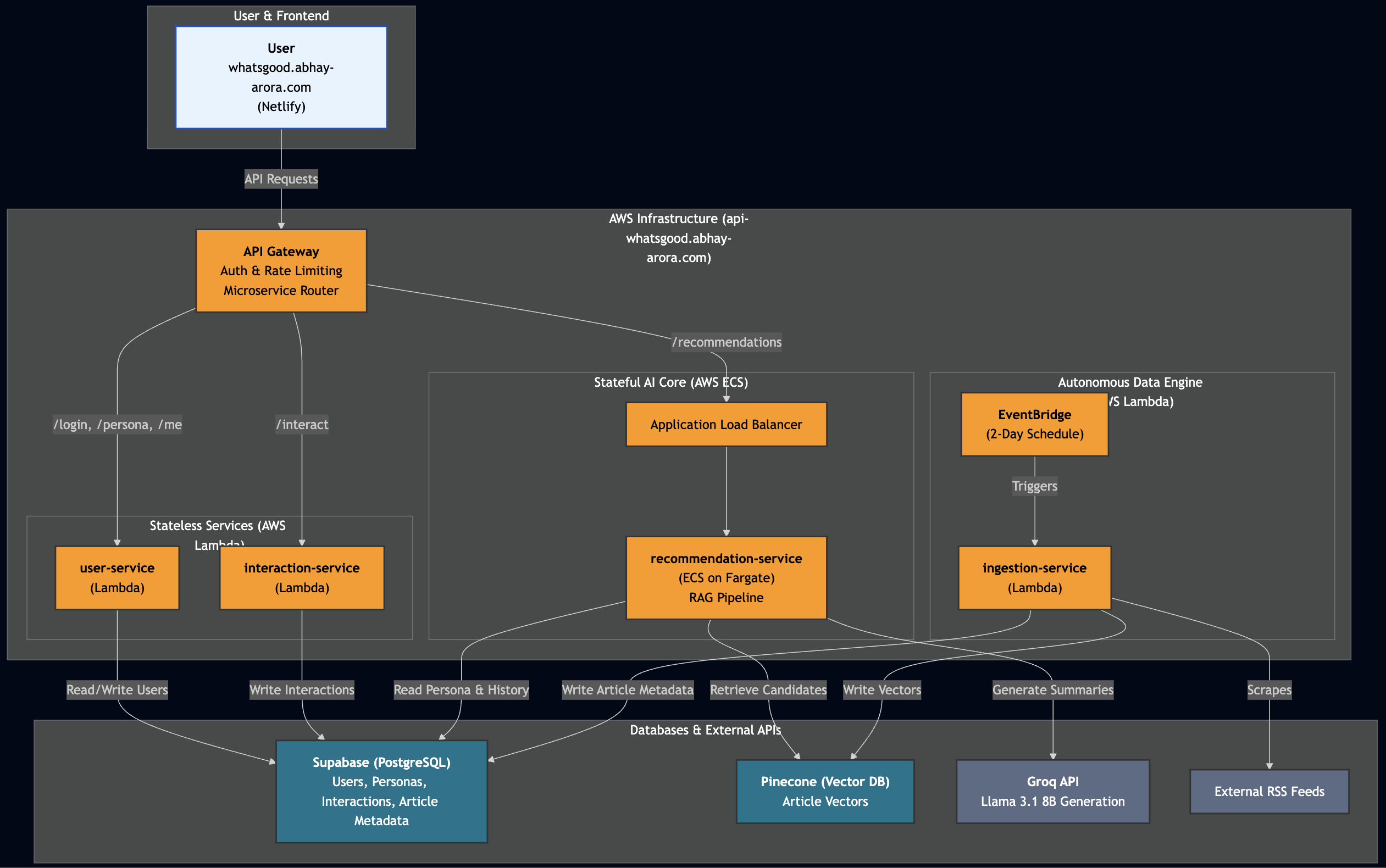
System Architecture: Distributed from Day One
To balance compute performance with operational costs, I avoided a monolithic design. Instead, I routed workloads to the appropriate AWS compute layer:
- Stateful AI Core (Always On): The recommendation service, which holds the Bi-Encoder and Cross-Encoder models in memory, runs on AWS ECS (Fargate) behind an Application Load Balancer to guarantee sub-second response times.
- Stateless Services (Serverless): The user interaction service and the background data ingestion service run on AWS Lambda. Migrating the scraping and ingestion layer to an event-driven Serverless architecture reduced compute costs by 60%.
Core Mechanics
1. Dynamic Persona Memory via Vector Interpolation
To eliminate the "stateless amnesia" problem, user profiles are not stored as static text. I implemented real-time vector interpolation using NumPy. When a user likes or dislikes an article, the system fetches their base vector and the recent interaction vectors, then performs vector arithmetic to dynamically shift their persona. This achieves highly personalized context with an 850ms p95 retrieval latency.
# From: services/recommendation-service/main.py
async def get_dynamic_query_vector(user_id: str) -> np.ndarray:
# ... (Fetch base_vector and interaction data) ...
dynamic_vector = base_vector
weight = 0.2 # Interaction pull weight
for item in interaction_response.data:
article_id = item['article_id']
interaction_type = item['interaction_type']
if article_id in fetched_vectors:
article_vector = np.array(fetched_vectors[article_id])
if interaction_type == 'like':
dynamic_vector = dynamic_vector + weight * (article_vector - dynamic_vector)
elif interaction_type == 'dislike':
dynamic_vector = dynamic_vector - weight * (article_vector - dynamic_vector)
return dynamic_vector / np.linalg.norm(dynamic_vector)2. Multi-Stage Re-Ranking
To ensure temporal relevance alongside semantic accuracy, I built a multi-stage retrieval pipeline. The system pulls 50 initial candidates from Pinecone and re-ranks them using a more accurate Cross-Encoder combined with a time-decay freshness score.
# From: services/recommendation-service/main.py
# ... (Inside Stage 4: Re-rank) ...
# 1. Pinecone's "fast" vector score
p_score = pinecone_scores.get(article_id, 0.0)
# 2. The "slow & accurate" Cross-Encoder score
c_score = cross_scores[i]
c_score_normalized = 1 / (1 + np.exp(-c_score)) # Normalize to 0-1
# 3. The freshness score (0.0 to 1.0)
f_score = get_freshness_score(article['published_date'])
# The final, weighted formula
final_score = (
(0.60 * c_score_normalized) + # 60% weight to accuracy
(0.30 * p_score) + # 30% weight to vector similarity
(0.10 * f_score) # 10% weight to freshness
)3. LLM Curation & Structured Output
Finally, the full text of the top 5 re-ranked articles is passed to Llama-3.1 (via Groq). To ensure the frontend didn't crash from non-deterministic text generation, I had to enforce strict structured outputs. I prompted the model to act as an analyst and mandated that it return a strict JSON array, mapping the reasoning traces directly to the article IDs.
# From: services/recommendation-service/main.py
system_prompt = """You are an expert news analyst.
Read the context and write a single, sharp hook for each article.
CRITICAL: Return your response as a single, valid JSON array.
The JSON array must contain exactly 5 objects.
Each object must have ONLY these keys: "id", "title", "summary", "reason".
Do not output any markdown formatting or conversational text outside the JSON."""Engineering Challenges & Solutions
Deploying this system to production surfaced several MLOps bottlenecks:
Fargate CPU Throttling & Latency Optimization
Problem: Initial stress testing revealed that concurrent requests exhausted AWS Fargate CPU credits, causing p95 latency to spike to an unacceptable 17 seconds.
Solution: The bottleneck was sequential network I/O waiting on LLM summary generation. I refactored the pipeline to use asynchronous fan-out execution (asyncio.gather) and tuned the re-ranking window. This shifted the workload from CPU-bound to I/O-bound, dropping end-to-end latency from 17s to 6s and resolving the throttling issue entirely.
Lambda Initialization Timeouts
Problem: The ingestion service on AWS Lambda failed due to the hard 10-second container initialization timeout, as the 1GB sentence-transformer model could not be loaded into memory fast enough during a cold start.
Solution: I moved the model payload out of the Docker image and attached it via EFS to the Lambda's /tmp directory. I then implemented a lazy-loading handler that initializes the model inside the execution function on the first invocation, successfully bypassing the init timeout limit.
Cross-Platform Architecture Mismatches
Problem: Building ARM64 Docker images on a local ARM machine (M3 Mac) using standard GitHub Action runners (x86_64) resulted in subtle emulation failures, causing instant container crashes upon deployment to AWS.
Solution: Engineered a dedicated QEMU-based CI/CD pipeline using Docker Buildx within GitHub Actions to force true cross-compilation. This ensured stable, native ARM64 image generation for the production environment.
The API Identity Crisis
Problem: Initially, I used FastAPI wrapped in mangum for all my Serverless Python services. For simple ingestion or interaction-logging endpoints, the FastAPI overhead was adding 100+ lines of boilerplate, unnecessary dependencies, and increasing the cold-start time for no tangible benefit.
Solution: The ultimate abstraction is removing the abstraction. I ripped FastAPI out of the lightweight microservices and rewrote them as pure, 30-line native AWS Lambda handlers. By manually parsing the JSON and returning the exact HTTP headers API Gateway expects, I drastically reduced the package size, cold-start latency, and point-of-failure surface area.